Find a plane that separate the classes in feature space.
Soften what we mean by separates and enrich and enlarge the feature space so that separation is possible.
Three methods for SVM
Maximum Margin Classifier
Support Vector Classifier(SVC)
Support Vector Machine(SVM)
1.1 Hyperplane
A hyperplane in p dimensions is a flat affine subspace of dimension p-1.
General equation for a hyper plane : \(\beta_0 + \beta_1 X_1 + ... \beta_p X_p = 0\)
If \(X = (X_1, ..., X_p)^T\) satisfies above, then \(X\) lies on the hyper plane.
If \(X = (X_1, ..., X_p)^T\) does not satify above, then \(X\) lies to on the side of the hyperplane.
1.2 Separating Hyperplanes
If \(f(x) = \beta_0 + \beta_1 X_1 + ... + \beta_p X_p\), then \(f(x) > 0\) for points on one side of the hyperplane, and \(f(x) < 0\) for points on the other.
If a separating hyperplane exists, we can use it to construct a very natural classifier.
For a test observation \(x^{*}\) : \(f(x^*) = \beta_0 + \beta_1 x_1^* + ... + \beta_p x_p^*\)
If \(f(x^*) > 0\), we assign the test observation to class 1.
If \(f(x^*) < 0\), we assign the test observation to class 2.
If \(|f(x^*)|\) is relatively large, the class assignment is confident.
If \(|f(x^*)|\) is relatively small, the class assignment is less confident.
2. Maximal Margin Classifier
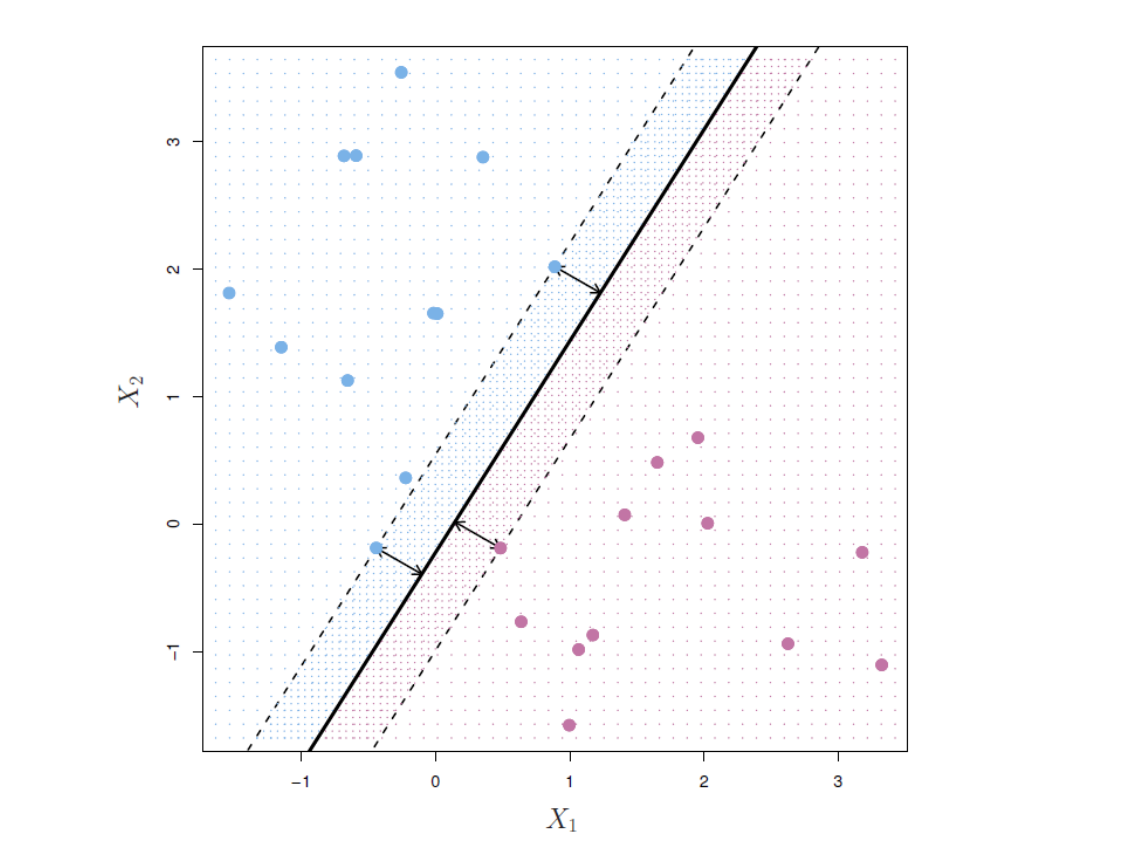
The maximal margin hyperplane is the separating hyperplane that is farthest from the training observations.
Among all separating hyperplane, find the one that makes the biggest gap or margin between the two classes.
Constrained optimization problem :
maximize M subject to
The function svm() in an R package e1071 solves this problem efficiently.
2.1 The Non-separable Case
The maximal margin classifier is a very natural way to perform classification.
However, in many cases no separating hyperplane exists, and so there is no maximal margin classifier.
If a separating hyperplane doesn't exist, there is no solution to M in the optimization problem.
However, we can develop a hyperplane that almost separates the classes, using a so-called soft margin.
The generalization of the maximal margin classifier to the non-separable case is known as the support vector classifier.
3. Support Vector Classifier
We need to consider a classifier based on a hyperplane that does not perfectly separate the two classes, in the interest of
Greater robustness to individual observations
Better classification of most of the training observations
It could be worthwile to misclassify a few training observations in order todo a better job in classifying the remaining observations.
The support vector classfier (soft margin classifier) allows some observations to be on the incorrect side of the margin, or even incorrect side of the hyperplane.
The margin is soft because it can be violated by some of the training observations.
\(\epsilon_i \geq 0$, and $\sum_{i=1}^n \epsilon_i \leq C\)
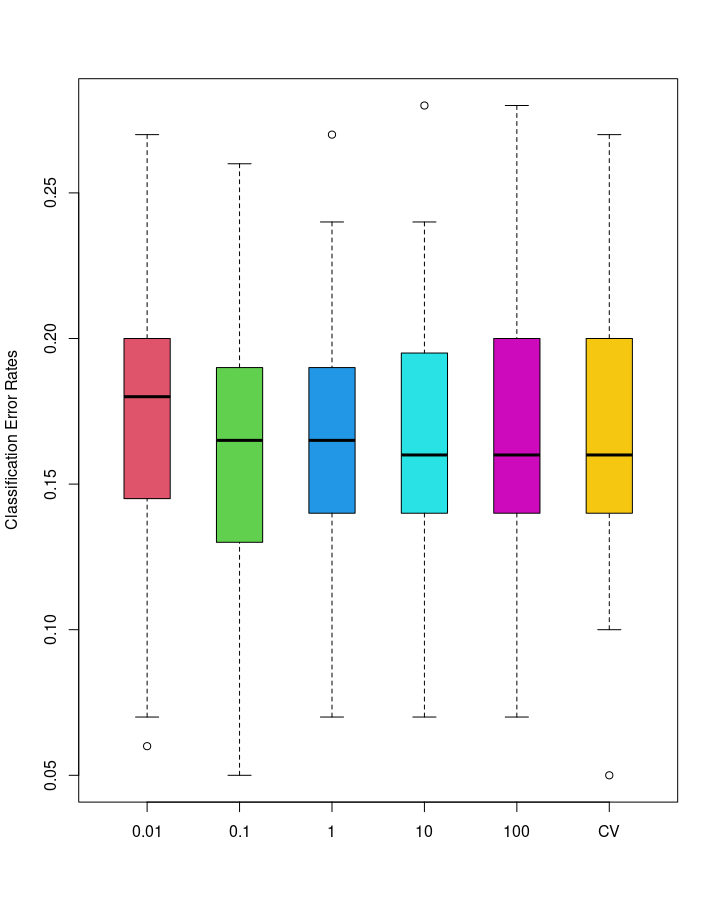
\(C\) is a tuning parameter.
3.1 Margins and Slack Variables
\(M\) is the width of the margin.
\(\epsilon_1, ..., \epsilon_n\) are slack variables.
If \(\epsilon_i = 0\), the \(i\)th obs. is on the correct side of the margin.
If \(\epsilon_i > 0\), the \(i\)th obs. is on the wrong side of the margin.
If \(\epsilon_i > 1\), the \(i\)th obs. is on the wrong side of the margin.
3.2 [Ex] Support Vector Classifier
# Simple example (simulate data set)
set.seed(1)
x <- matrix(rnorm(20*2), ncol=2)
y <- c(rep(-1, 10), rep(1, 10))
x[y==1, ] <- x[y==1, ] + 1
plot(x, col=(3-y), pch=19, xlab="X1", ylab="X2")
# Support vector classifier with cost=10
library(e1071)
# y must be in format (-1, 1)
dat <- data.frame(x, y=as.factor(y))
# Tuning parameter cost (inverse of C)
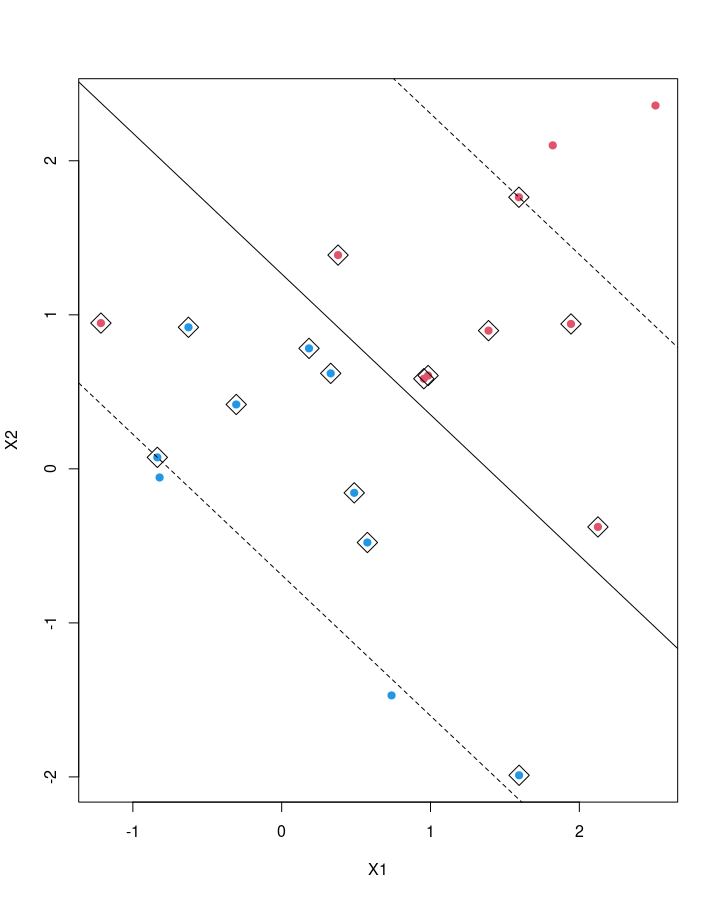
svmfit <- svm(y~., data=dat, kernel="linear", cost=10, scale=FALSE)
plot(svmfit, dat)
summary(svmfit)
3.3 [Ex] Support Vector Classifier with different margins