1. Dropout
Dropout layer can help correcting overfitting. Overfitting is caused by the network spurious patterns in the training data. To recognize these spurious patterns a network will often rely on very specific combinations of weight, a kind of "conspiracy" of weights. Being so specific, they tend to be fragile : remove one and the conspiracy falls apart.
This is the idea behind dropout. To break up these conspiracies, we randomly droupout some fractions of layer's input units every step of training, making it much harder for the network to learn those spurious patterns in the training data. Instead, it has to search for broad, general patterns, whose weights patterns tend to be more robust.
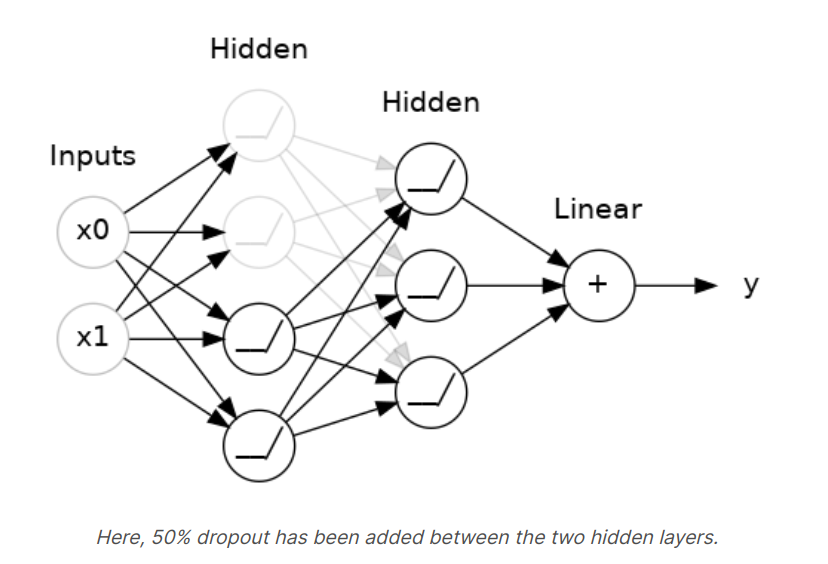
We could also think about dropout as creating a kind of ensemble of networks. The predictions will no longer be made by one big network, but instead by a committee of smaller networks. Individuals in the committee tend to make different kinds of mistakes, but be right at the same time, making the committee as a whole better than any individual.
In Keras, the dropout rate argument rate defines what percentage of the input units to shut off. Put the dropout layer just before the layer we want the dropout applied to.
Keras.Sequential([
# ...
layers.Dropout(rate = 0.3), # apply 30% dropout to the next lay
layers.Dense(16),
# ...
])
2. Batch Noramlization
With neural networks, it's generally a good idea to put all of our data on a common scale, perhaps with something like scikit-learn's StandardScaler or MinMaxScaler. The reason is that SGD will shift the network weights in proportion to how large an activation the data produces. Feature that tend to produce activation of very different size can make for unstable training behavior.
Now, if it's good to minimize the data before it goes into the network, maybe also normalizing inside the network would be better? In fact, we have a special kind of layer that can do this, the batch normalization. A batch normalization layer looks at each batch as it comes in, first normalizing the batch with its own mean and standard deviation, and then putting the data on a new scale with two trainable rescaling parameters. Batchnorm, in effect, perfroms a kind of coordinated rescaling of its input.
Most often, batchnorm is added as an aid to the optimization process (though it can sometimes also help prediction performance). Models with batchnorm tend to need fewer epochs to complete training. Moreover, batchnorm can also fix various problems that can cause the training to get stuck. Consider adding batch normalization to our models, especially if our're having trouble during training.
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),
3. Optimized Neural Networks
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(1024, activation='relu', input_shape=[11]),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=100,
verbose=0,
)
# Show the learning curves
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();
Source from : https://www.kaggle.com/learn
'Data Science > Neural Network' 카테고리의 다른 글
| [Tensorflow] Binary Classification (0) | 2022.09.22 |
|---|---|
| [Tensorflow] Overfitting and Underfitting (0) | 2022.09.21 |
| [Tensorflow] Stochastic Gradient Descent (0) | 2022.09.21 |
| [Tensorflow] Deep Neural Networks (0) | 2022.09.21 |
| [Tensorflow] A Single Neuron (0) | 2022.09.20 |



