1. What is Web Scraping
Web Scraping, Web Harvesting, Web Extraction is data scraping used for extracting data from websites. The web scraping software may directly access the World Wide Web using the Hyper Transfer Protocol or a web browser. While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web scraper
2. How to scrape data from a Web
- Find the URL that you want to scrape
- Inspecting the Page
- Find the data you want to extract
- Write the code
- Run the code and extract data
- Store the data int the required format
Pandas have various applications and there are different libraries for different purpose.
- Selenium : Selenium is a web testing library. It ise used to automate browser activities.
- BeautifulSoup : BeautifulSoup is a Python package for parsing HTML and XML documents. It creates parse trees that is helpful to extract data easily.
- Pandas : Pandas is a library used for data manipulation and analysis. It is used to extract the data and store it in the desired format.
3. Web Scraping
Step 1 : Find the URL that you want to scrape
I am going scrape PassMark Software website to extract the Name, and Average G3D Marks of Gpu card. The URL for this page is https://www.videocardbenchmark.net/high_end_gpus.html.
Step 2 : Inspecting the Page
The data is usually nested in tags. So, we inspect the page to see, under which tage the data we want to scrape is neted. To inspect the page, just right click on the element and click on "Inspect".
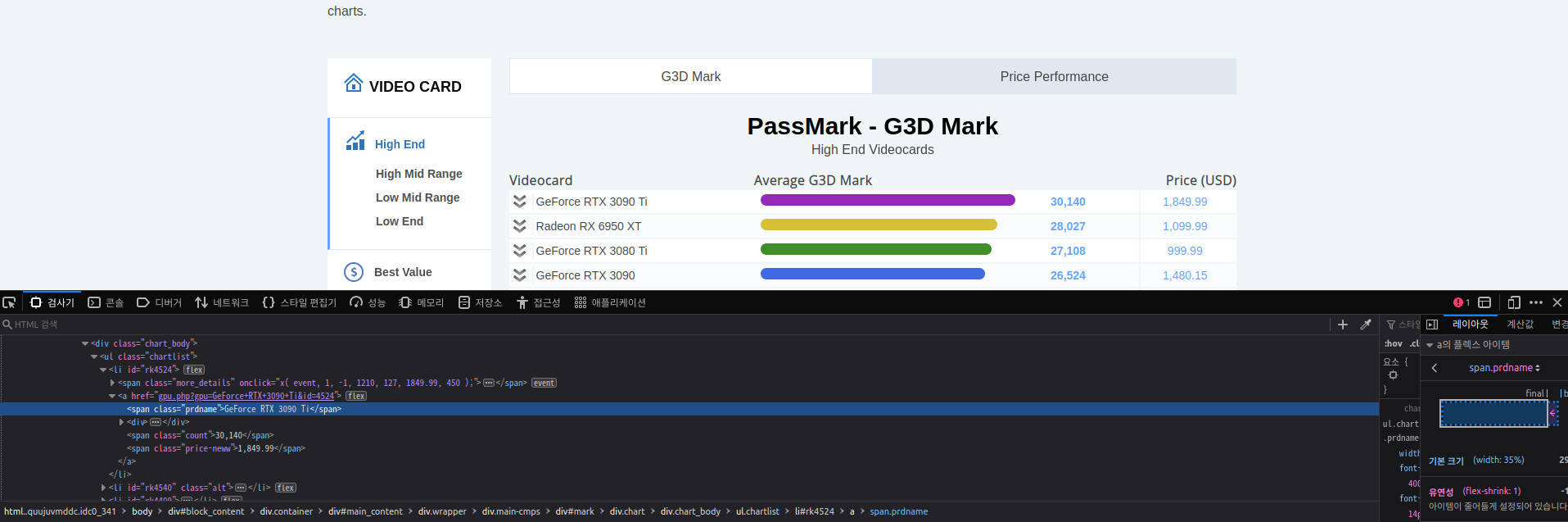
Step 3 : Find the data you want to extract
What we want to scrape is in <div class='chart_body'>.
Step 4 : Write the code
First, let us import all the necessary libraries.
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as pd
To configure webdriver to use FireFox browser, we have to set the path to geckodriver.
driver = webdriver.Firefox(executable_path = '/usr/bin/geckodriver')
Refer the below code to open the URL :
products = []
g3d_marks = []
driver.get("https://www.videocardbenchmark.net/high_end_gpus.html")
When we use driver.get(url), driver get all of the html tags from web pages. Now that we have written the code to open the URL, it's time to extract data from the website. The data to extract is nested in <div> tags. So we need to find the div tags with those respective class-name, extract the data and store the data in a variable.
products = []
g3d_marks = []
driver.get("https://www.videocardbenchmark.net/high_end_gpus.html")
content = driver.page_source
soup = BeautifulSoup(content)
# findAll method return all tags in html pages
for prdname in soup.findAll('span', 'prdname') :
product = prdname.text
products.append(product)
for count in soup.findAll('span', 'count') :
counts = count.text
g3d_marks.append(counts)
df = pd.DataFrame({'Gpu' : products, 'G3D_Marks' : g3d_marks})
df.head()
Our scraped table will be same as below :

Source from : https://www.edureka.co/blog/web-scraping-with-python/
Web Scraping With Python - Full Guide to Python Web Scraping
In this web scraping with Python tutorial, you will learn about web scraping and how data can be extracted, manipulated and stored in a file using Python.
www.edureka.co
'Language > Python' 카테고리의 다른 글
| [folium] Visualization Map on Python (0) | 2022.09.18 |
|---|---|
| [heapq] Implementing Binary Heap in Python (0) | 2022.09.14 |
| [queue] Implementing Priority Queue in Python (0) | 2022.09.14 |
| [Syntax] Exception (0) | 2022.09.14 |
| [beautifultable] Print List in Table Format (0) | 2022.09.14 |
